The following notes are to assist you if your work placement does not provide their own instruction. Continue to do your own research and ask colleagues in the work place for advice.
Flat file databases
A flat file database is simply a table of data that stores all the information about a given object in a row.

You can see that some information has been added in multiple places. This will increase the size of the database and can lead to the following issues:
- Insert anomalies
- Delete anomalies
- Update anomalies
An insert anomaly is where you can’t add new information to the table because you are lacking part of the row. In the above example you can’t add a new department until you have the teacher’s details.
A delete anomaly is where deleting the information about a given object also removes all the information about a related object. In the above example Marie Macleod could retire. But if we remove her entry then we lose all the data about the maths department.
An update anomaly happens when you update a row with new information but fail to update a row that shares the information. In the above example we could update the telephone number for the English department on Donal Morrison’s row but forget to make the update to Julie Stevens’. Now there are two telephone numbers listed for the English department.
Relational databases
- AKA Linked Databases
- Relational DataBase Management System(RDBMS)
- MS Access, MySQL, MariaSQL, Microsoft SQL Server, Oracle
A relational database splits the data into multiple tables. The aim being to only have data about an object stored in a single place. These data objects are then linked with relations.
The data in the previous example can be split into two tables. One stores the data about the department, and one stores the data about the teacher including an identifier stating in which department they work.
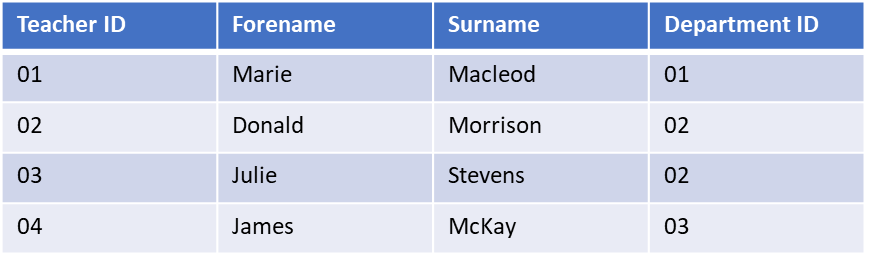
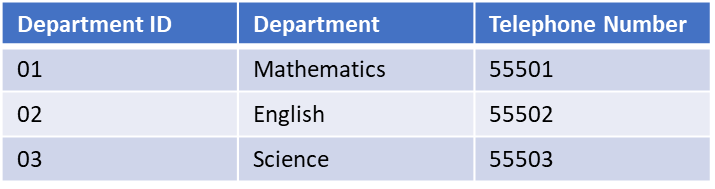
We’ve now split the data into two tables.
Each table contains data about a single object type: Teachers and Departments.
By assigning a Department ID to each teacher we can look up all the information about that department.
This has fixed all the anomalies. Any change should now only have to alter a single row.
In an RDBMS an entity set is represented by a table.
Entities (rows)
In an RDBMS an entity is represented as a row in a table. A row stores all the data about a given object. This row of data can also be called an Entity. An entity stores information about an object or something we want to record.
An entity is made up of multiple attributes or fields.
An entity should only store data relevant to that object or a key to relate it to another table.
For example a garage might make a database for their customer details. But it would not make sense to store the vehicle details in the same table as the customer details. A customer might have multiple vehicles.
Strong entities – An entity that has an independent existence, i.e. doesn’t rely on another entity.
Weak entities – An entity that relies on another entity to exist.
Example. A table containing staff details could hold strong entities, but a table containing next of kin details would be weak as the entities within are only needed based on a staff entity.
Attributes
Entities are made up of attributes. These store the individual properties of data about an entity.
There are various types of attribute:
- Simple attribute – These attributes are atomic. We cannot break them down further. e.g – id, first_name, etc.
- Composite attribute – These attributes are a collection of simple attributes. e.g. – Name can consist of first_name, middle_name and last_name.
- Derived attribute – These attributes are not available in the database, but we can find them using other attributes. e.g. – We can derive age using the date_of_birth.
- Single-valued attribute – These attributes only have a single value. e.g.- student_id
- Multi-valued attribute – These attributes can have multiple values. e.g. – email, phone_number
Domains
Domain refers to a set of permitted values we can assign to an attribute.
For example, age must be a positive integer. Or we could have a colours attribute that can only be one of the values: “Red”, “Blue”, “Yellow” or “Green”.
Data types
Databases can store different types of data in a field.
- Text field – Stores words, numbers, special characters etc
- Number field – Stores integers, floats etc
- Date field – Stores dates
- Time field – Stores times
- Date/Time fields – Some databases will use a single type for both Date and Time
- Boolean – Stores a True or False value.
Relationships
Remember how we’re dealing with Relational DataBase Management System(RDBMS)? So what are these relationships?
Relationships are how tables are linked to each other. How an entity in one table might rely on an entity (or entities) in another table.
Relationships can be described with 3 constraints: Degree, Cardinality and Participation
Degree
Unary
A unary relationship occurs when the table has a relationship with itself.
Example – A staff table could have a supervisor column that refers to another member of staff.
Binary
The most common relationship is where one entity has a relation with another.
Example – A staff table has a binary relation with a next of kin table.
Ternary
In a ternary relationship there are 3 entities all relating to one another.
Example – A staff table is in a ternary relationship with a department and manager table.
N-ary
In a n-ary relationship there are N entities all relating to one another. N-ary relationships are thankfully uncommon.
Cardinality
Relationships between two tables can be categorised into one of the following:
One-to-one
Example – A member of staff must have a single next of kin record
One-to-many
Example – A member of staff might have multiple pieces of company equipment assigned to them
Many-to-many
Example – Members of staff might be on multiple training courses.
Participation
Mandatory (full)
In a mandatory relation, all the entities must exist and be related.
Example – all employee entities must have a contact details entity linked to them.
Optional (partial)
In an optional relation, the entities and relations exist as needed.
Example – employee entities might have one or more company equipment entities linked to them.
Keys
Keys are used to identify entities.
Primary keys
A primary key is a field that can uniquely identify an entity in a table.
Usually it will be an id such as a number that automatically increments each time an entity is added to the table.
But if unique data exists within the table you can use that as the primary key. For example a table that has a National Insurance number or a student ID in a school could use that as a primary key.
The Entity Integrity rule states that every table must have a primary key column containing values that are unique and not null.
Surrogate key
A surrogate key is just when a field is created specifically to be a key. In other words there was no naturally occurring unique data in that table.
So an auto incrementing number added just to uniquely identify an entity is both a surrogate and primary key.
Composite key
A composite key is when two or more fields are used in conjunction to uniquely identify an entity.
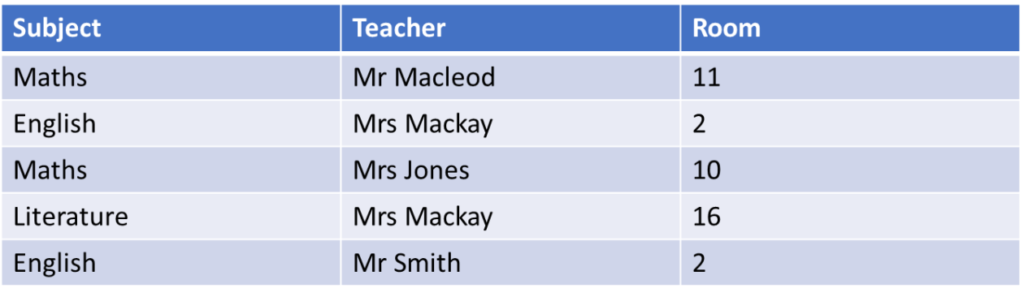
We can’t use either the subject or teacher to find the room as each subject and teach occurs multiple times. But we can use a composite made from the subject and teacher as a key.
Foreign keys
Foreign keys are attributes that contain the primary key of another table. They are used to identify a relationship between the tables.
For example a next of kin table might have a column called employee_id which stores the id from the employee table where it is a primary key. In the next of kin table this employee_id column is a foreign key.
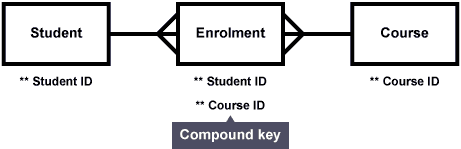
Compound keys
Compound keys are similar to composite keys in that they use two or more fields together to make a unique identifier.
Compound keys use foreign key attributes to form the key for this table.